MVPcode|2025.02–03
Early in 2025, AI coding and vibe coding were everywhere, and the idea that “one idea is enough to make a product” was very common. At that time I had some early sparks of product thinking, but I still didn’t know how to build a complete web product. On one hand, I was asking how to get a web app running end to end; on the other, I was asking whether this idea itself could be turned into a product.
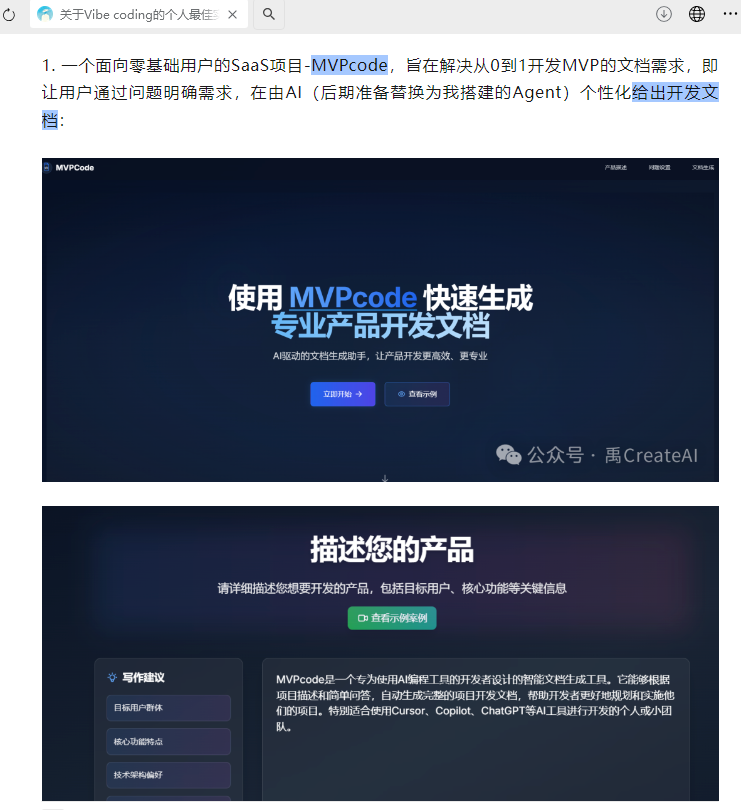
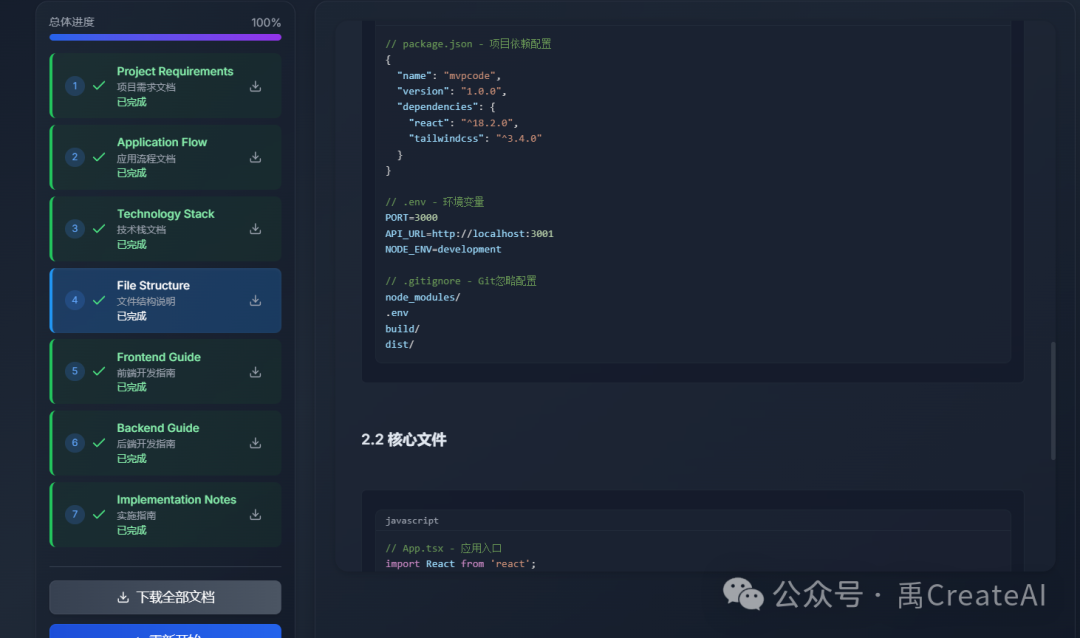
I had learned a product model that broke the pre-build phase into seven documents: project requirements, application flow, tech stack, file structure, frontend development, backend development, and implementation notes. Starting from that, I built an AI app specifically for generating those documents.
The frontend was very simple — looking back, it was basically an AI-generated blue-purple gradient. The backend directly called an LLM API, returned a one-shot output, and processed it into seven documents.
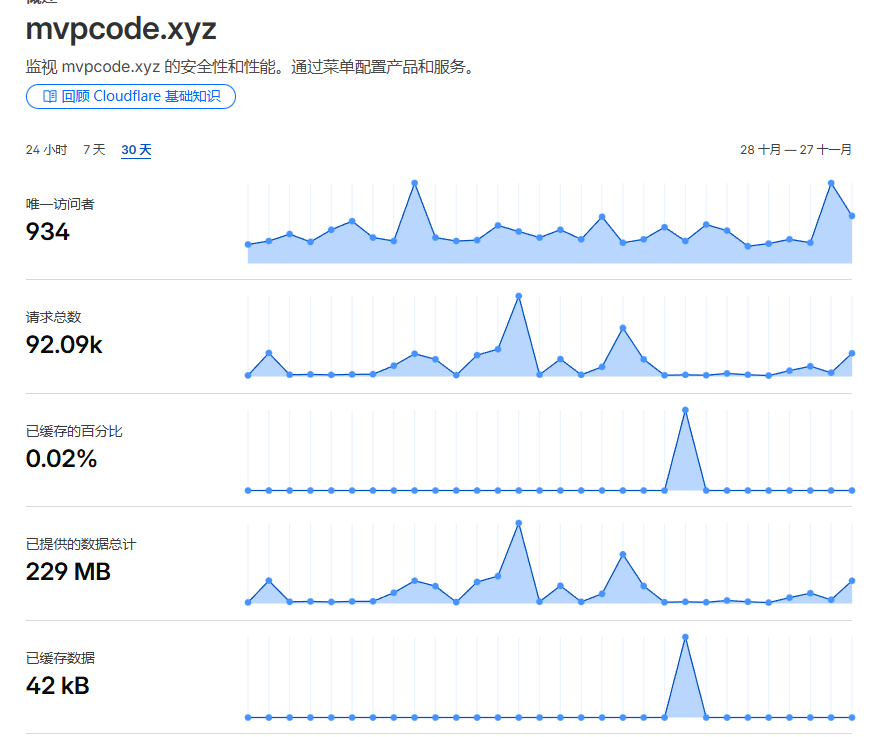
This gave me a concrete understanding of how a web product moves from a real starting point to development and deployment. Later I shared it in a large AI community, and Cloudflare analytics showed close to a thousand visits at peak. I didn’t keep pushing the product forward, and slowly realized that this kind of demand wasn’t strong enough to require its own standalone product. Still, I had turned an idea into a real application.
NEXUS|2025.08–12
A full-stack chatbot whose core was designing around agents: dynamically building context each time by retrieving past conversations from the database, short- and long-term memory through a sliding window over message history plus a reflection agent that extracted traits from conversations and stored them, and the introduction of simple web tools.
Originally, I wanted to focus on a memory-centered chatbot, but I didn’t keep it contained. I spent a lot of energy polishing other parts instead of specifically researching how to organize AI context so it could have continuity or memory.
Through this process, I developed some thoughts about software engineering. AI at that time wasn’t good at architectural decomposition: logic became tightly coupled, the codebase grew, and if complexity wasn’t managed well, everything became exhausting. My workflow then was to talk one-on-one with an architecture agent, settle the design in documents, and then let a coding agent implement it. Overall it was document-driven development, and I also used test-driven development in practice, with very good results.
There were also issues of overdesign. The project started from the idea of a memory-bearing “companion” for myself and people around me, yet I chose a fairly heavy cloud database, MongoDB, mainly because it had native vector indexing. Looking back, I didn’t have the concept of “local-first” then — even simple markdown or jsonl would have been enough. I also hadn’t thought hard enough about what the project was ultimately for; I was a bit too immersed in the building process itself.
I also began thinking about context engineering for agent development.
AION|2025.10–12
The first two projects could still be called products. AION was more of a philosophy-driven experiment: if you give AI an environment without presetting a purpose, what can it become? The idea sounded great, but in the end it made me realize that AI and agents still need to serve people. Once detached from human problems and real situations, AI can’t really be called autonomous — it is still a tool.
Given the model capabilities at the time, giving it an environment already meant giving it a purpose. Without guidance, the agent had no initiative; context was too slow to load; the agent’s action space was too narrow, so it only used certain tools in the same patterns. Later I realized the importance of progressive disclosure. As model capabilities improved, models became capable of actively loading context and doing things on their own — but only if the guidance was right.
AION already used a heartbeat mechanism like OpenClaw to wake itself up on a schedule, but the latter had real user information, which made it more capable of proactively digging for value.
That gave me a deeper understanding of context engineering. It also made me realize that engineering depends on logic. If imagination cannot be turned into logic, engineering cannot stand, and neither can the project. AI autonomy still depends on human context.
opencontext|2026.02
With coding TUIs like Claude Code and Codex growing more powerful and their toolsets becoming more complete, many experienced developers hardly write code by hand anymore and instead use AI coding. The shared pain point is still that agents don’t know what we already know. Alignment in communication keeps going wrong, and decisions made earlier in a project get repeated because AI doesn’t know them. At the core, it’s still a context problem.
opencontext is a CLI for agents. It organizes local coding-agent session records into project briefings, so when work resumes next time, AI reads those briefings first instead of exploring everything from scratch again. In that sense, the CLI is simply a tool for AI: use it when needed to see previous decisions.
Later I realized this isn’t only missing in coding. Many AI collaboration problems come from context not being properly organized.
HaL|2026.02–04
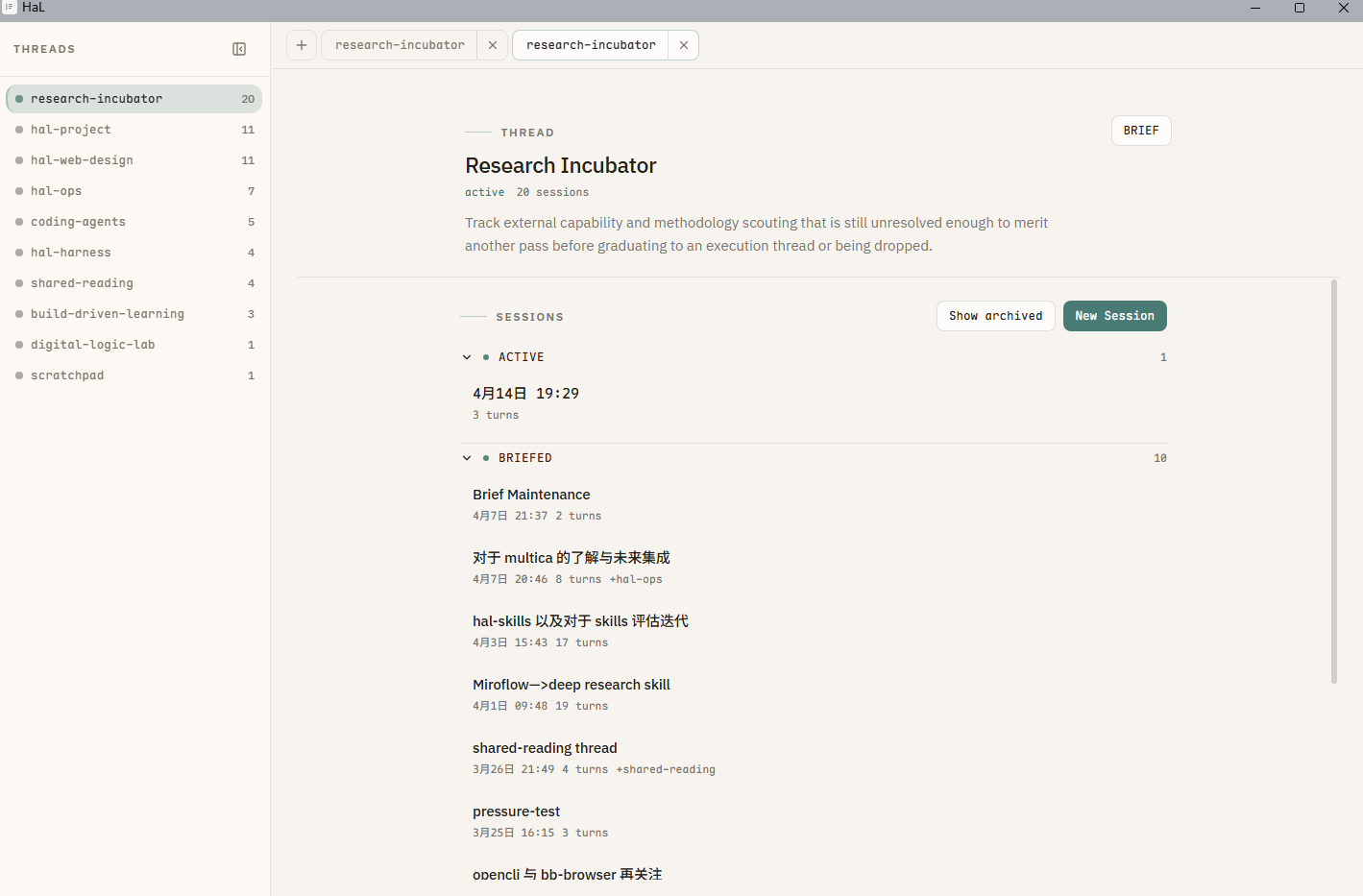
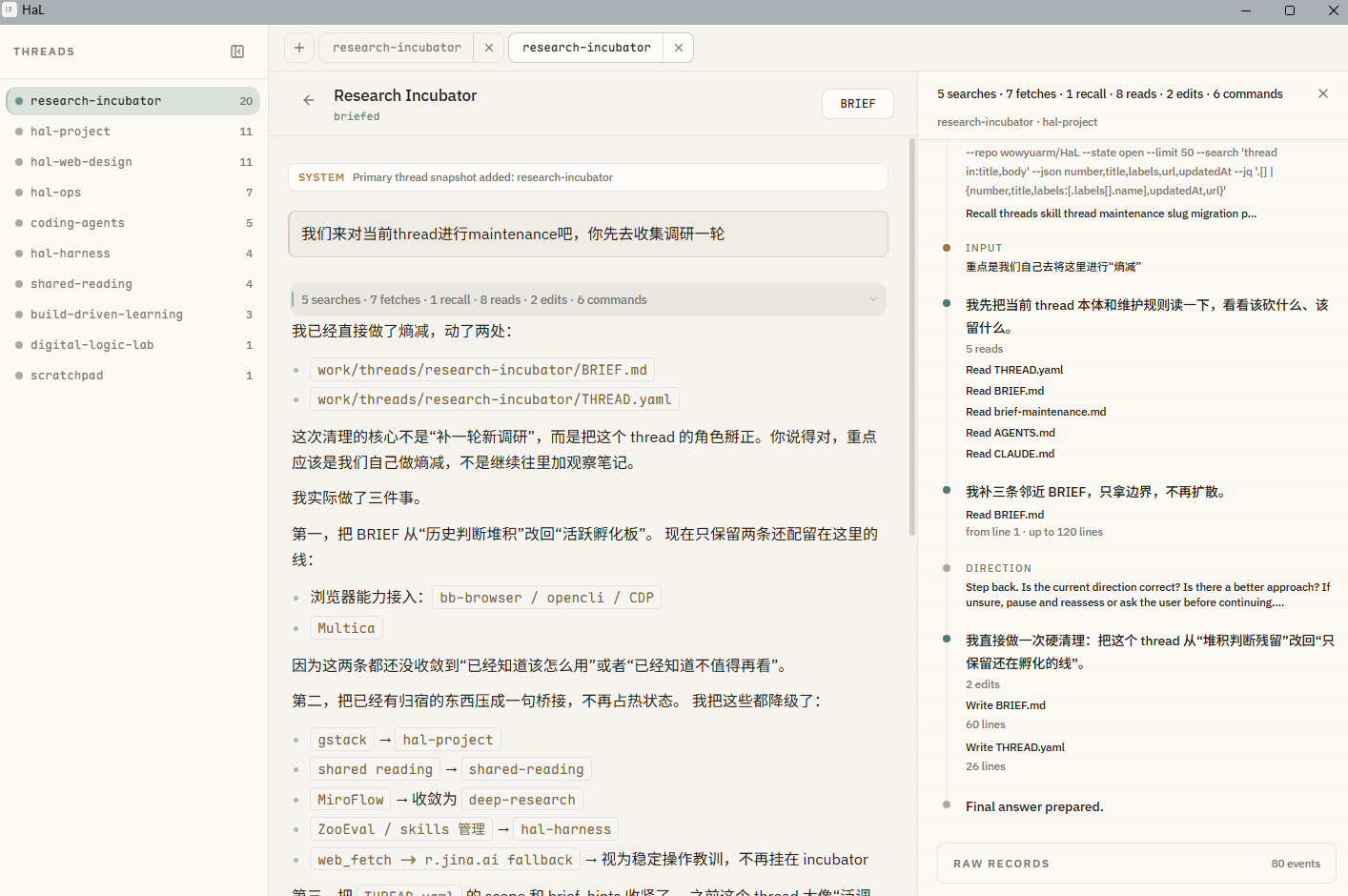
Many of the projects I built share the same core issue: providing context for agents. HaL is the same.
It’s somewhat like a management application. Human-AI collaboration can raise productivity, but many things are not delivered in one shot — they unfold across weeks or months. During that time, people can remember project state and decisions, but AI cannot, and even automatic memory is often inaccurate.
HaL manages conversation state manually by theme (thread) and by conversation. Through commands, it continually distills task state, background, and progress. Within the same theme, important context keeps accumulating, and sometimes even process details I hadn’t consciously noticed turn out to be very useful.
“How do you design a way of collaborating that can keep moving forward over time?” is the question HaL needs to answer.
opencontext and HaL both left me with an extremely strong feeling about the current generation of model-based coding agents: in the future, agents will definitely be able to complete most digital tasks, but context engineering — and more recently harness engineering — may become as important to agents as software engineering is to software.
prune|2026.04
A Rust CLI built specifically for agents to inspect repositories, find files, and read context. Agents use bash to interact with the operating system, but many traditional commands were designed for humans, and their output is often noisy for models. prune is a CLI built specifically for agent use in searching, reading, and other context-gathering operations.
I also know that models have seen far more operations like bash in training data, so bash is a natural tool for AI. Later I built evaluations around this project to compare the difference between using bash and using the prune CLI; I also built a framework of my own, starting from evaluation, to keep improving it.
This gave me a better understanding of what it means to give an agent an environment for self-evaluation and evolution, solving the problem AION had when it lacked a goal. For the AI working on prune, I gave it one purpose: optimize prune itself. With that single goal, the AI could use the evaluation and evolution framework around the project to run tests, make changes, and iterate on it.
But there are framework problems too. In many commits, the actual effect still diverges from what looked improved; and the problem of agents optimizing for optimization also exists — treating modification itself as the goal rather than real optimization.
Looking back, these projects were probably not mature products meant for distribution. They were experiments that started from questions or ideas, and through actually building them I accumulated some judgments.
Overall, I now have a complete understanding of the lifecycle of a web product or a full-stack project. I also understand some lower-level principles of models and the higher-level construction built on top of them. Because of that, I have a relatively clear understanding and judgment of AI agents: internal loops, context construction, tool frameworks, model providers, framework environments, and how to use AI to quickly turn a product into reality — from research and product prototyping to page design, feature iteration, and deployment.
I still run into plenty of problems: lacking real product feedback and external validation, and many things truly begin from a geek’s perspective. Sometimes I can also get too immersed in building itself. Real work needs real problems and real users.
MVPcode|2025.02–03
25 年初,AI coding、vibe coding 很火,“一个想法就能够做产品”这类说法也很常见。那时我对产品思维有一些模糊的萌芽,但还不知道怎样完整地做出一个 web 产品。一方面,我在想“如何跑通一个 web app”;另一方面,也在想这个想法本身能不能被产品化。
当时我知道一个产品模型,会把产品成型前拆成 7 份文档:项目需求、应用流程、技术栈、文件结构、前端开发、后端开发、实施指南。就从这里出发,我构建了一个专门生成这些文档的 AI 应用。
前端很简单,现在回头看基本就是 AI 生成的蓝紫渐变;后端则是直接调用 LLM API,返回一次性内容,再把结果处理成 7 份文档。
这个项目让我对一个 web 产品如何从现实问题出发,一路走到开发与部署,有了更具象的认识。后来我在一个千人 AI 社区里分享过它,Cloudflare 的统计里最高接近千次访问。产品最终也没有继续往下推,我慢慢意识到,这类需求并没有强到必须依赖一个独立产品来承载。不过,它的确把一个想法落成了具体应用。
NEXUS|2025.08–12
一个全栈 chatbot,核心是围绕 agent 来设计:每次动态构建上下文,从数据库中检索并召回过去的对话;同时做长短期记忆,用历史消息滑动窗口,再加一个 reflection agent 从对话里提取一些特征并记下来;另外也引入了简单的联网工具。
本来出发点是做一个侧重记忆的 chatbot,但最后没有收住,花了很多精力去打磨其他部分,而不是专门研究如何组织 AI 的上下文,让它真正具有连续性或者记忆。
在这个过程中,我也形成了一些对软件工程的想法。当时的 AI 还不太擅长做架构拆分,代码逻辑容易耦合,代码量一上去,如果复杂度管理不好,人就会非常累。我那时采用的工作流是,先单独和一个架构 agent 沟通,把设计写进文档,再让 coding agent 去具体实施。整体上是文档驱动开发,实际过程中也用了测试驱动开发,效果很好。
另外也有一些过度设计的问题。项目出发点其实只是给自己和身边人做一个有记忆的“伙伴”,技术选型却比较重,用了云端数据库 MongoDB,当时主要看中它原生支持向量索引。现在回头看,那时我还没有“本地化”这个概念,甚至简单的 markdown、jsonl 就已经足够了。还有一点是,我没有想得足够清楚:这个项目到底是为了什么;某种程度上,我有些过于沉浸在 building 的过程本身了。
也是从那时开始,我对 agent 开发里的上下文工程,也就是 context engineering,有了一些思考。
AION|2025.10–12
前面两个项目都还算得上产品,AION 则更偏向一个由哲思驱动的实验:给 AI 一个环境,但不预设什么目的,它会变成什么样?这个想法本身很好,但最终也让我意识到,AI、agent 还是需要服务于人。脱离了人的问题与场景,AI 谈不上真正的自主性,归根结底还是工具。
结合当时的模型能力来看,给它一个环境,其实也等于给了它一个目的。没有引导,agent 就没有主动性;上下文加载太慢,agent 的动作空间又太窄,最后只会反复用特定工具,遵循同样的模式。后来我意识到渐进式披露的重要性。随着模型能力继续上升,model 的确会越来越有能力主动加载上下文、自己去做事,但前提仍然是引导要到位。
AION 当时就用了和 OpenClaw 一样的 heartbeat 机制来定时唤醒,但后者会带有用户的真实信息,因此也更具主动性去挖掘信息与价值。
这让我对上下文工程有了进一步理解。也让我意识到,工程依赖于逻辑;如果想象无法转化为逻辑,工程就很难成立,项目也没有真正的立足点。AI 的自主性,归根到底还是依赖于人类上下文。
opencontext|2026.02
随着 Claude Code、Codex 这些 coding TUI 越来越强,工具也越来越完整,很多资深开发者几乎已经不再手写代码,而是直接使用 AI coding。这里面共同的痛点还是:agent 不知道我们已经知道的东西。沟通对齐总会出问题,项目里一些之前已经做过的决策,后面 AI 不知道,又会再犯一遍。核心还是 context 不够。
opencontext 是一个供 agent 调用的 CLI。它会把本地 coding agent 的会话记录整理成项目简报,这样下次继续做的时候,AI 会先读这些简报,而不是重新从头摸索。整体上,这个 CLI 就相当于 AI 的一个工具:需要时就去调用,看看之前的决策。
后来我也发现,不只是 coding 会缺少这种决策上下文,很多 AI 协作问题,本质上都是上下文没有被整理好。
HaL|2026.02–04
自己做的不少项目,核心问题其实都是给 agent 提供上下文,HaL 也是如此。
它有点像一个管理类应用。人与 AI 的协作的确会提高生产力,但很多事情不是一次就能落地,而是会跨越数周甚至数月。在这段时间里,人能够记得项目的状态和决策,AI 却不会;就算有自动 memory,往往也不一定准。
HaL 是按主题(thread)、按具体对话去手动管理对话状态,再通过命令持续沉淀任务状态、背景和推进过程。在同一个主题下,一些重要的上下文会不断积累下来,甚至会出现一些我自己当时都没有意识到、但后来非常有用的过程信息。
“如何设计一种可以持续推进的协作方式?”是 HaL 需要回答的问题。
opencontext 与 HaL,都让我对现阶段基于模型能力的 coding agent 有一种极其强烈的感受:未来的 agent 一定能够完成大部分数字任务,但上下文工程,以及近来的 harness engineering,可能会像软件工程之于软件那样重要。
prune|2026.04
一个专门给 agent 看仓库、找文件、读上下文用的 Rust CLI。agent 会通过 bash 和操作系统交互,但过去很多命令都是服务于人的,它们的输出对 model 来说往往很繁杂。prune 就是专门给 agent 调用,用来做搜索、读取等获取上下文操作的 CLI。
我也知道,模型在训练数据里其实见过更多 bash 这种操作,所以 bash 对 AI 来说是一种很自然的工具。后来我围绕这个项目搭了评测,去比较 model 使用 bash 工具和使用 prune 这个 CLI 的区别;也搭了一套从评测出发、供自己持续改进的框架。
这让我对“给 agent 一个可以自我评测、自我演化的环境”有了更具体的认识,也解决了 AION 当时缺乏目标的问题。我给 prune 里的 AI 只设定了一个目的:优化 prune 本身。围绕这个目标,AI 就可以借助项目里的评测和演化框架,自己去跑测试、做修改、迭代项目。
但这里面也有框架本身的问题。很多 commit 最后会发现,表面上的优化和实际效果仍然会有偏差;agent 为了优化而优化的问题也存在,它会把“修改”本身当成目的,而不是真正去优化。
回头看,这些项目大概都不是为了分发而做的成熟产品,更像是从问题或想法出发的一系列实验,而我也在实际构建中慢慢积累起了一些判断。
总的来说,我现在对一个 web 产品、一个全栈项目的生命周期流程,已经有了比较完整的认识。也理解了一些模型底层原理,以及建立在其上的上层构建。基于这些,我对 AI agent 会有一个相对清晰的理解与判断:内部循环、上下文构建、工具框架、模型服务商、框架环境的搭建,以及如何用 AI 快速把一个产品落到现实里——从实际调研,到产品原型,再到页面设计、功能改进与部署上线。
当然,也还是会遇到不少问题:缺乏真实的产品反馈、缺乏外部验证,很多事情的出发点也确实偏向极客视角,有时我也会沉浸在 building 本身。真正的落地,还是需要真实的问题与真实的用户。